서울시 범죄현황 통계자료 분석 및 시각화 (2)
안녕하세요?
오늘은 구름 인공지능 수업에서 배운 서울시 범죄현황 통계자료 분석 및 시각화를 복습해보는 2번째시간입니다. 저번 시간까지는 exel로 이루어진 서울시 관서별 5대 범죄 현황 데이터 입력하고, 이 데이터를 경찰서의 구별로 정리하고 검거율을 계산하고, 인구 데이터를 merge하는 것까지 했습니다.
또 마지막에는 지금까지 전처리해온 데이터들을 잠깐 시각화하여 범죄별로 데이터의 크기가 너무 다른 것까지 확인할 수 있었습니다.
저희가 궁극적으로 하고싶은 것은 구별로 범죄발생 현황비율을 시각화하는 것이기 때문에 이렇게 데이터들끼리 크기가 맞지 않으면 나중에 문제가 생길수도 있습니다.
오늘은 간단히 데이터 정규화방법들과, axis 연산에 대해 살펴보도록 하겠습니다.
저희가 지금까지 전처리해온 데이터프레임 gu_df에서 강도, 살인, 절도, 폭력 등 값을 알고 있는 열의 이름을 x-data라 부르는데,
이 X-data(열)을 부르는 또다른 이름들로는 column, attraibute, dimention, feature등이 있습니다.
이 때 지금 저희가 하려는 X-data의 크기들이 서로 맞지 않을 때 보통 feature의 scale 맞지 않는다고 표현을 하며,
feature의 scale을 맞추는 대표적인 2가지 방법은 Min-Max Algorithm과 Standardiztion이 있습니다.
1. Min-Max Algorithm
- 열마다의 최솟값을 0, 최대값을 1로 맞춰주는 방법
- newX = ( oldX - min(열) ) / ( max(열) - min(열) )
2. Standardization
- 열마다의 평균값을 0, 표준편차값을 1로 맞춰주는 방법
- newX = ( oldX - mean(열) ) / std(열)
많은 사람들이 직관적인 min-max를 많이 쓰지만, 실제로 예측모델을 만드는 과정에서는 standardization이 모델의 성능을 높이는 ‘경향’을 보인다고 합니다.
지금은 범죄별로 가장 많이 발생한 구를 1로 만들어주는 (min-max와 standardi와 비슷하지만 많이 쉬운) 정규화를 하도록 하겠습니다.
weight_col = gu_df[[‘강간‘, ’강도’, ‘살인’, ‘절도’, ‘폭력’]].max()
crime_count_norm = gu_df([[‘강간‘, ’강도‘, ’살인‘, ‘절도’, ‘폭력’]] / weight_col
crime_count_norm
이 다음엔 구별로 폭력 발생 순위를 기준으로 내림차순 정렬하여 시각화를 해서 데이터들을 살펴보도록 하겠습니다.
plt.figure(figsize=(10,10))
sns.heatmap(crime_count_norm.sort_values(by=‘폭력‘, ascending=False), annot=True, fmt=‘f’, linewidths=.5, cmap=‘RdPu’)
plt.title(‘범죄 발생(폭력발생으로 정렬) - 각 항복별 최대값으로 나눠 정규화’)
plt.show() 해당 heatmap을 보게되면 폭력뿐만아니라 절도, 강간, 강도 등에서도 강남구가 꽤나 높은 순위를 가지고있음을 볼 수 있습니다.
그런데 정말로 우리나라에서 강남구는 진짜 사람이 거주하기 무서운 동네가 되는 것일까요?
잘 생각해보면, 우리가 데이터를 전처리 하는동안에 한가지 놓친부분이 있습니다.
바로 인구수입니다. 강남은 서울 중에서도 인구가 너무 많아 절대적인 범죄 발생 수치는 높게 나올 수 밖에 없을 것입니다.
마지막으로 행(구)별 범죄 수(max대비 비율값)을 구별 인구수로 나누어준 다음 인구 수 단위인 10만을 곱해주는 마지막 전처리 작업을 거치도록 하겠습니다.
(9.795665e-07같이 표시될 숫자들을 0.xx까지 끌어올리기 위해서입니다.)
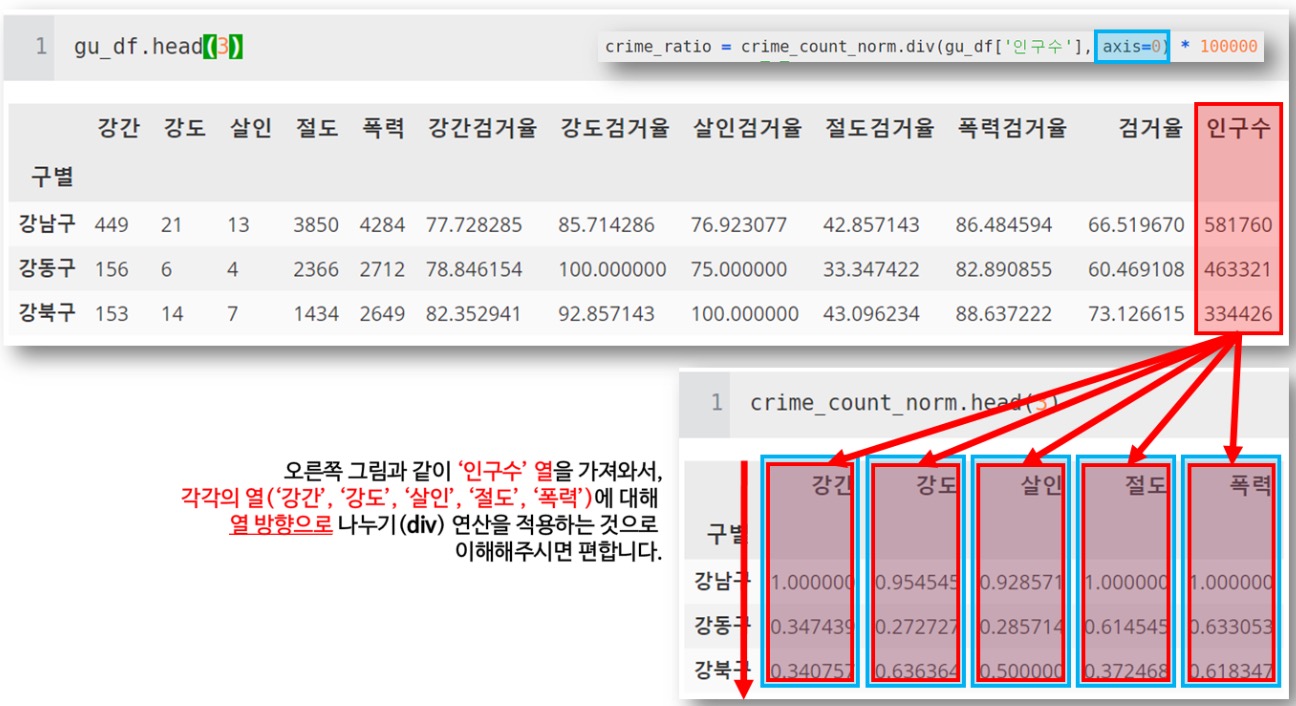
crime_ratio = crime_count_norm.div(gu_df[‘인구수‘], axis=0) * 100000
crime_ratio_head()여기서 한가지 짚고 넘어가고 싶은 것이 있는데, 바로 df.div() 함수의 axis부분입니다.
aixs=0일 경우 열 방향으로 모든 행을 따라가며 연산을 진행하고
axis=1일 경우 행 방향으로 모든 열을 따라가며 연산을 진행한다고 이해하시면 되겠습니다.
axis=0은 행을 따라가는 열방향 연산, axis=1은 열을 따라가는 행방향 연산 !!!
이렇게 한 후에 한 번 다시 폭력 발생 기준 구별 순위를 살펴볼까요?
plt.figure(figsize=(10,10))
sns.heatmap(crime_count_norm.sort_values(by=‘폭력‘, ascending=False), annot=True, fmt=‘f’, linewidths=.5, cmap=‘RdPu’)
plt.title(‘범죄 발생(폭력발생으로 정렬) - 각 항복별 최대값으로 나눠 정규화’)
plt.show() 이렇게 하면 강남구의 순위가 1위에서 밑으로 내려간 것을 확인해 보실 수 있습니다.
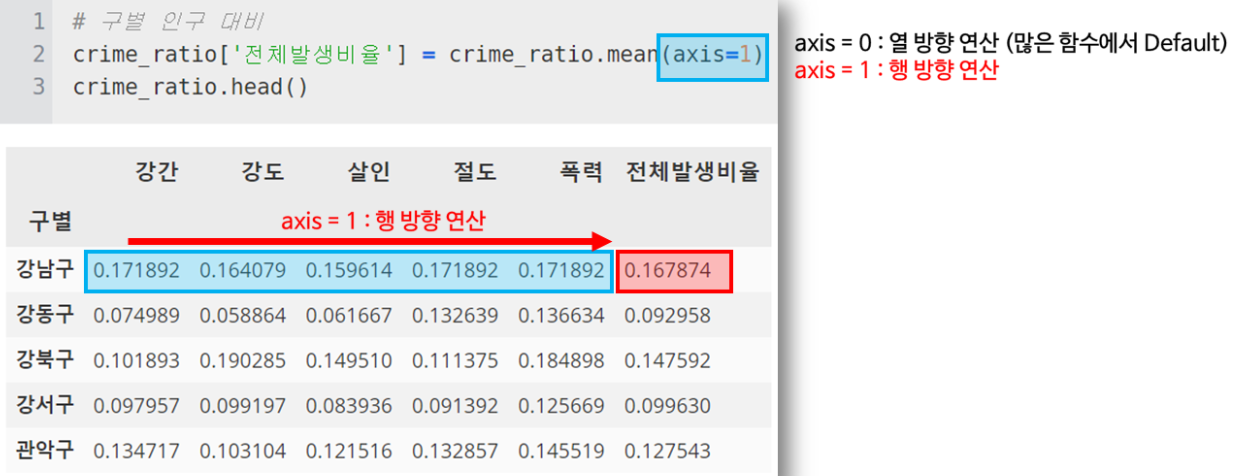
다음으론 인구수 대비 구별 5대범죄 발생 수치 평균(전체발생비율)을 한번 볼까요?
crime_ratio[‘전체발생비율‘] = crime_ratio.mean(axis=1)
crime_ratio.head()(실제로 여기서 저는 바로 평균을 구하였지만, 폭력과 살인의 심각수준은 너무 다르기때문에 가중평균을 구하는게 좋을 수도 있겠습니다.!)
여기서 다시 axis=1은 행방향 연산임을 잊지 않고!! 넘어갑시다.
오늘은 짧게 여기까지하고 …
다음시간부터는 본격적으로 데이터를 지도 시각화하는 법에 대해 복습해보도록 하겠습니다.