서울시 범죄현황 통계자료 분석 및 시각화 (4)
안녕하세요!!!
오늘은 구름 인공지능 교육에서 배운 서울시 범죄현황 통계자료 분석 및 시각화의 복습을 마무리 지어보는 시간을 가져보도록 하겠습니다!!
저번시간까지는 서울시 5대 범죄현황의 데이터들을 전처리하고 그 전처리한 데이터들을 간단히 시각화하면서 확인도 해보았고 -> folium을 활용하여 구별로 잘 정돈되어있는 데이터들을 서울시 지도 위에 얹어 시각화하는 것까지 해보았습니다.
오늘 해볼 것은 구별 시각화에서 더 나아가 googlemaps API를 이용하여 구글맵에서 서울시 각 경찰서의 위도, 경도 정보를 받아온 다음
이 경찰서들의 검거율을 원으로 나타내어 서울시 지도 위에 얹어 시각화해보는 시간을 가져보도록 하겠습니다.!
먼저 오늘 활용할 데이터를 한번 훑어보도록 하겠습니다.
(오늘은 각 경찰서별 데이터가 필요하니, 지금까지 구별로 정돈되었던 gu_df가 아닌 기존의 데이터였던 df를 불러오도록 하겠습니다.)
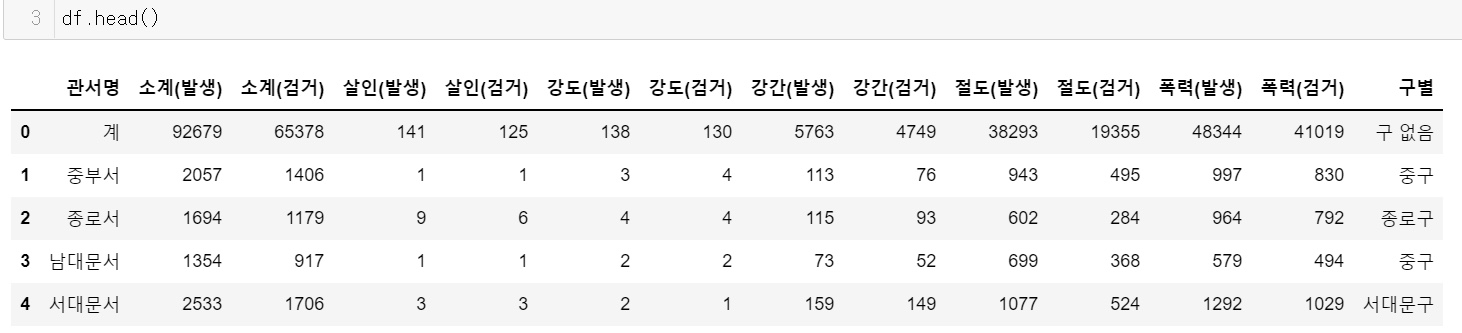
이제 df에 ‘경찰서’열과 ‘검거율’열을 추가해서 넣어주도록 하겠습니다.
(경찰서 이름은 관서명에서 ‘서’ 앞글자들을 따와 뒤에 ‘서’ 대신 ‘경찰서’를 붙여주도록 하겠습니다. + 구글맵에서 경찰서 좌표를 얻기 위해서는 경찰서의 풀네임이 필요하므로 앞에 ’서울‘도 붙여주겠습니다!! ex.중부서->서울중부경찰서)
df = df.drop([0])
station_name = []
for name in df[‘관서명‘] :
station_name.append(‘서울’ + str(name[:-1]) + ’경찰서’)
df[’경찰서‘] = station_name
df[’검거율‘] = df[‘소계(검거)’]/df[‘소계(발생)’]*100
df.head()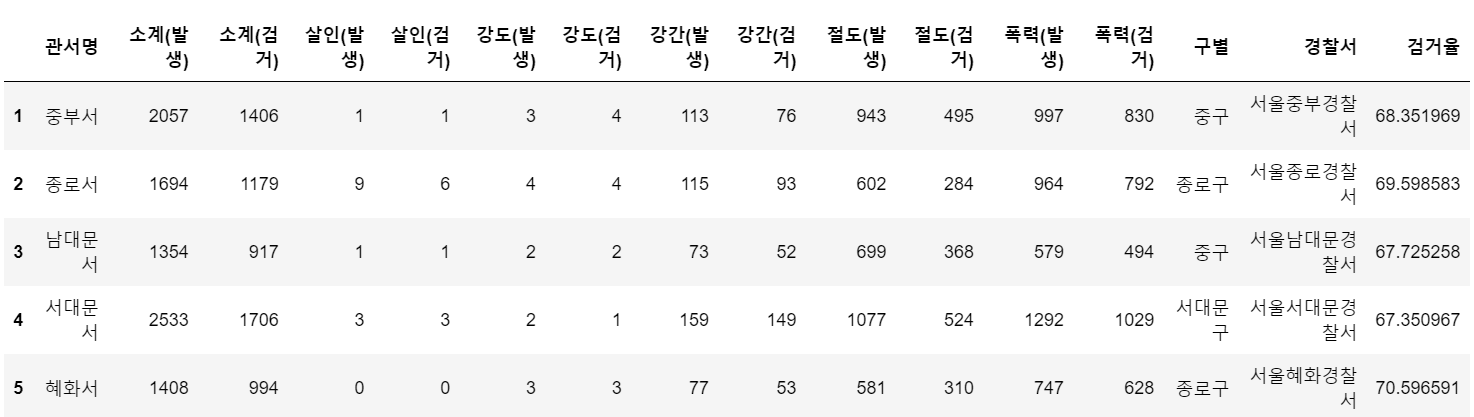
여기서 이제 검거율을 쭉 보시면 모든 데이터들이 60~80사이를 오가는 것을 볼 수 있습니다.
최솟값을 확인해보면 64이고 최대값은 81이 나오는데 이렇게되면 이를 나중에 원의 지름으로 사용하면 경찰서별 검거율의 원의 크기 차이가 별로 안나게 될 것입니다.
그래서 이 검거율 값을 최대를 100, 최소를 1로 바꾸는 작업을 한번 거쳐주겠습니다.
(이런 작업을 거칠 때 데이터가 왜곡이 되는지 안되는지를 봐야하는데 저희는 지금 데이터의 절대값이 중요한게 아니라 차이가 중요한 것이기 때문에 괜찮습니다.)
# ['검거율'] 열을 대상으로,
# 가장 낮은 검거율과 가장 높은 검거율을 가지는 경찰서를 일종의 점수 개념으로 간격을 벌림 (지도에서 보다 더 잘 비교되도록 하기 위함)
# 1) newMax-newMin 를 곱해주는 이유 : 0~1 대신에 특정한 range 로 변환 (여기서는 1~100)
# 2) newMin 인 1을 더해주는 이유 : 최소값인 0을 갖는 데이터가 시각화 시 아예 데이터가 표현되지 않는 것을 방지
def reRange(x, oldMin, oldMax, newMin, newMax):
return (x - oldMin)*(newMax - newMin) / (oldMax - oldMin) + newMin
df['점수'] = reRange(df['검거율'], min(df['검거율']), max(df['검거율']), 1, 100)
df.sort_values(by=‘점수‘, ascending=False, inplace=True)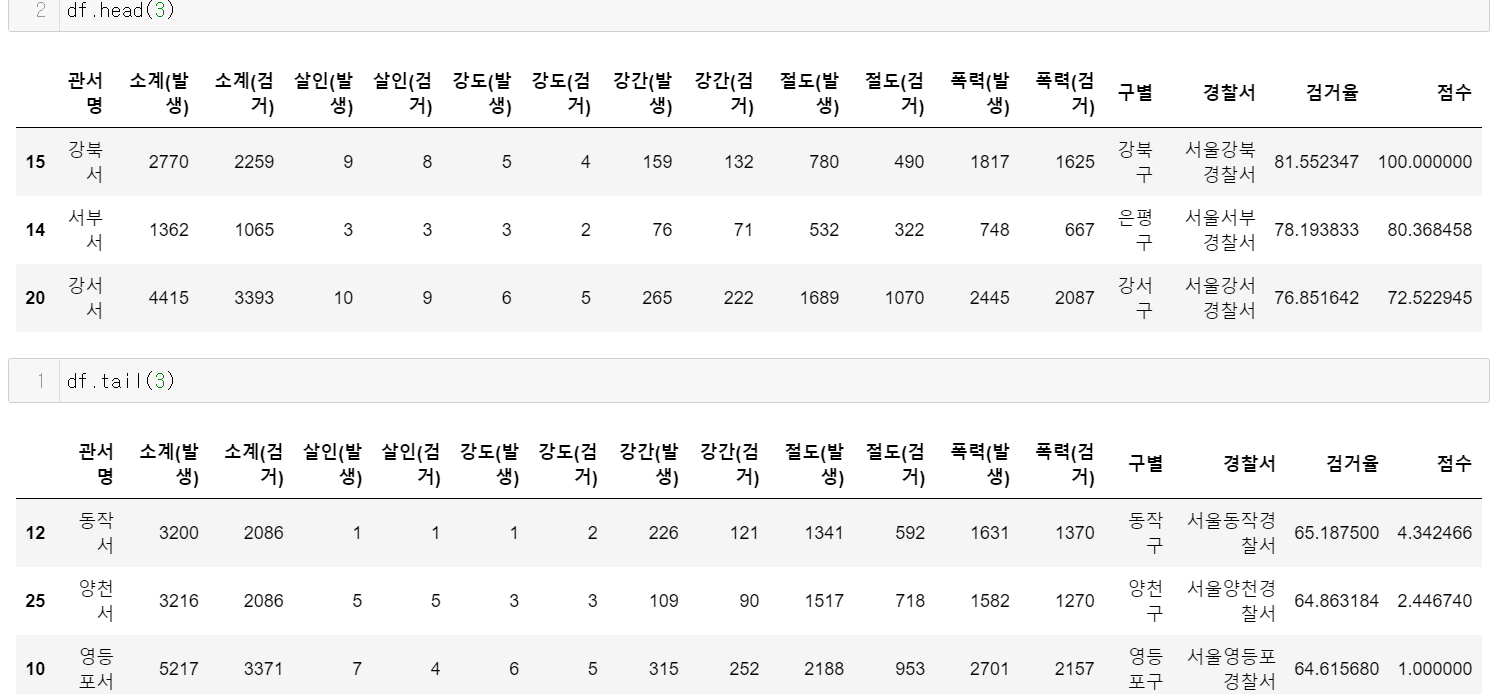
이제 필요로한 경찰서별 데이터가 잘 만들어졌으니 이제 구글맵스에서 경찰서별 좌표 데이터를 가져오는 작업을 해보도록 하겠습니다.!
그전에 먼저, 구글맵스 라이브러리를 사용하려면 구글맵스의 개인 API key값이 필요합니다.
과정이 그렇게 어렵진 않으니 자세한 내용은 아래에 정리해두도록 하겠습니다.
- 구글맵스 API key 받기 (영문) : https://developers.google.com/maps/documentation/geocoding/get-api-key (https://goo.gl/mU5NYK)
- 구글맵스 API key 받기 (국문) : https://goo.gl/P4dbxU
(구글 계정에 카드를 등록하여 결제가 가능한 상태가 되어야 합니다. 자세한 내용은 위 링크를 참고해주세요!)
(구글맵스 API key 받는 과정 요약)
-> GCP 콘솔 접속 @ https://console.cloud.google.com/google/maps-apis/overview
-> 새 프로젝트 생성
-> API 및 서비스 > 라이브러리 > "Geocoding API" 검색 > "사용 설정" 클릭
-> API 및 서비스 > 사용자 인증 정보 > "사용자 인증 정보 만들기" 클릭 > "API 키 만들기" 클릭 > key 값 복사 > "키 제한" 클릭
-> 하단 "API 제한사항" 탭 클릭 > Select API 드롭다운 메뉴에서 "Geocoding API" 를 찾아 클릭 > 저장
-> 복사해 둔 key 값을 Jupyter notebook 의 googlemaps.Client 의 인자 값으로 붙여넣고 실행합니다.
개인 API key를 복사하셨다면 한번 구글맵스를 통해 서울강남경찰서의 정보값들을 확인해보도록 하겠습니다.
!pip install googlemaps==4.6.0
import googlemaps
gmaps = googlemaps.Client(key=##여러분들의 개인키!!!복붙!!!##)
tmpMap = gmaps.geogode(‘서울강남경찰서‘, language=‘ko’)
# print(tmpMap) 한번 확인해보세용
tmpMap[0].get(‘geometry’)
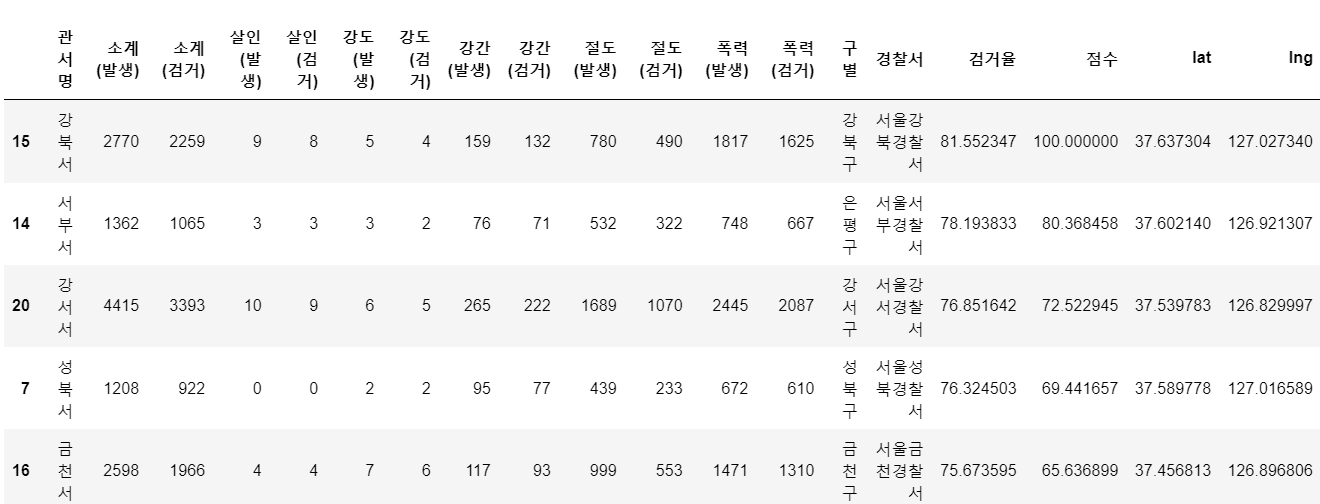
구글맵스에서 어떤 장소를 입력하면 데이터가 어떤형식으로 나오고, 위도 경도 값을 확인하려면 어딜 봐야하는지를 알았으니 바로 df에 각 경찰서별 위도 경도 값을 추가해주도록 하겠습니다.
lat = []
lng = []
for name in df['경찰서']:
# gmaps.reverse_geocode((longitude 값, latitude 값), language="ko") == 경도 & 위도 값으로 주소값 가져오기
# gmaps.geocode('한글 주소', language="ko") 로 위도/경도, 우편번호까지 알 수 있음
tmpMap = gmaps.geocode(name) # ex) 서울강남경찰서
tmpLoc = tmpMap[0].get('geometry') # 배열 형태( [~] )로 들어오기 때문에 [0]으로 호출
lat.append(tmpLoc['location']['lat']) # dict(tmpLoc)의 데이터는 dict['key값'] 로 value 호출
lng.append(tmpLoc['location']['lng'])
df['lat'] = lat
df['lng'] = lng
df.head()
자 이제 끝!!!!
모든 준비를 마쳤습니다.
이제 folium을 이용해서 서울시 지도 위에 각 경찰서별 검거율을 원으로 표시해서 시각화하고 비교해봅시다.
map = folium.Map(location=[37.5502, 126.982], zoom_start=11)
for n in df.index:
# range(len(df.index)) 처럼 할 필요 없이 바로 df.index 를 순회하여 record 자체에 접근할 수 있음
# 경찰서별로 원형 마커를 생성하여 점수를 radius 로 매겨 지도에 표시함
# folium.Circle() 의 경우는 radius가 자동으로 meter 단위가 됩니다. (아래 CircleMarker에서의 radius는 pixel 단위)
folium.CircleMarker ([df['lat'][n], df['lng'][n]],
radius=df['점수'][n]*0.5, # circle 의 크기를 결정
color='#3186cc', fill=True, fill_color='#3186cc').add_to(map)
map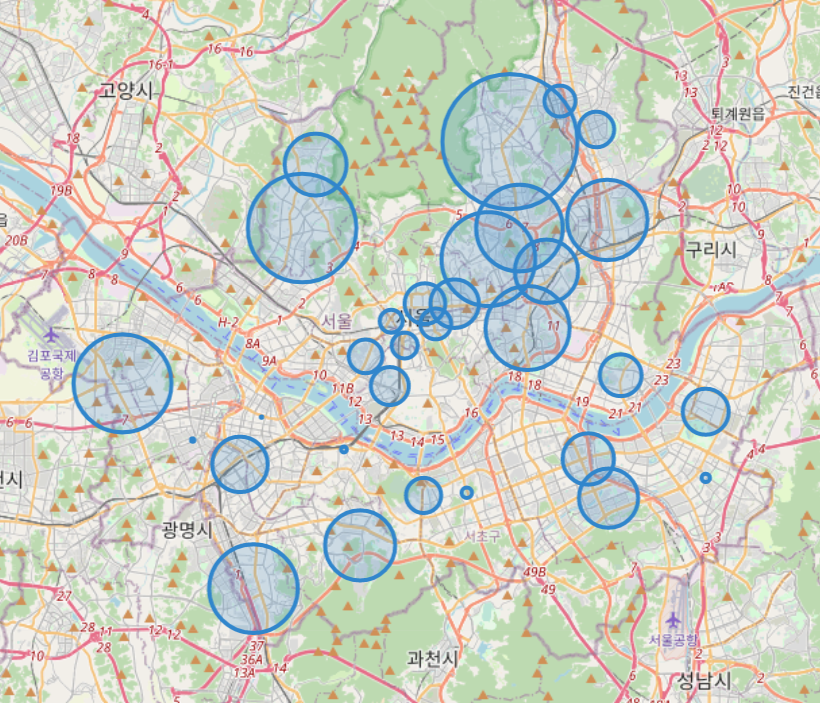
짠! 완성되었습니다.
그런데 조금 밋밋하죠?
어느 지역에 있는 경찰서가 범죄검거율이 제일 높은지는 대충 보이는데 그 경찰서가 어느 경찰서인지, 그 구에 범죄발생비율은 또 어땠는지도 함께 볼 수 있으면 좋을 것 같습니다.
한번해볼까요?
(저번시간에 했던 folium 코드들을 함께 사용하면 됩니다.)
(추가로, 마지막에 folium으로 만든 그림을 html로 컴퓨터에 저장하는 것까지 하고 마무리 하겠습니다.!)
map = folium.Map(location=[37.5502, 126.982], zoom_start=11.3)
map.choropleth(geo_data = geo_str,
data = crime_ratio['전체발생비율'],
columns = [crime_ratio.index, crime_ratio['전체발생비율']],
fill_color = 'PuRd', #PuRd, YlGnBu
key_on = 'feature.id')
for n in df.index:
folium.CircleMarker([df['lat'][n], df['lng'][n]],
radius=df['점수'][n]*0.7, # 0.5 -> 0.7
color='#3186cc', fill=True, fill_color='#3186cc').add_to(map)
folium.Marker ([df['lat'][n], df['lng'][n]], popup=df['경찰서'][n]).add_to(map)
map
# df.to_csv(‘processed_data.csv’, encoding=‘utf-8’) 혹은 euc-kr or cp949
map.save(‘folium_map.html’)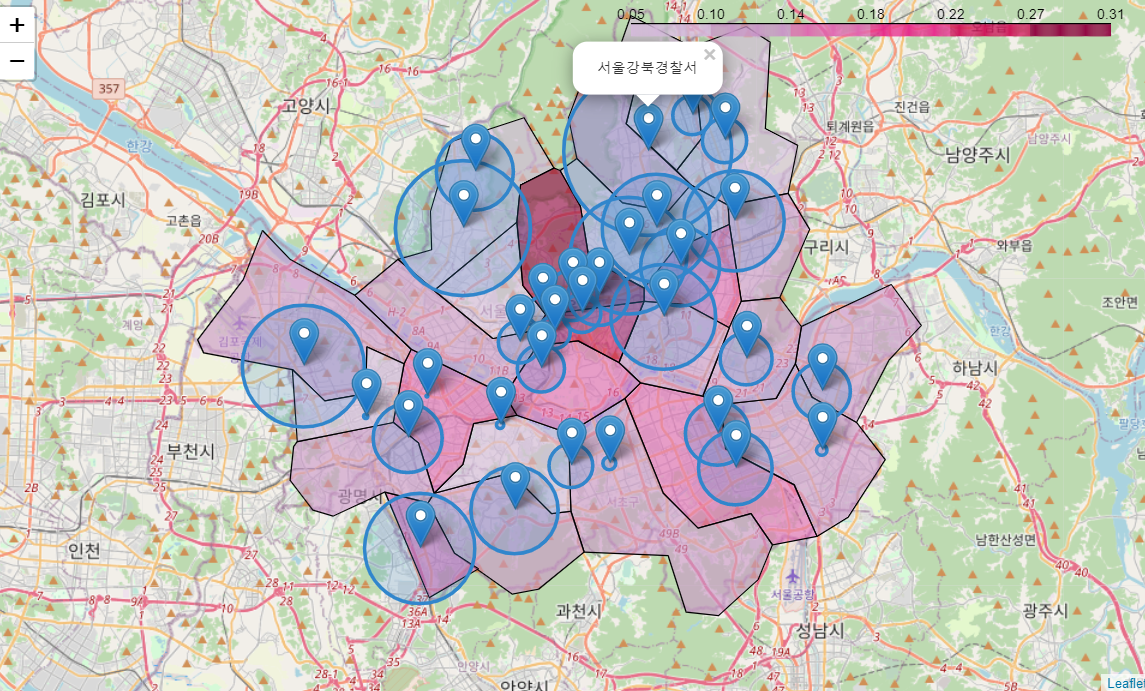
이상으로 서울시 범죄현황 통계자료 분석 및 시각화 활동 복습을 마무리하도록 하겠습니다.
수고하셨습니당 :)