프로그래밍/웹크롤링 & 텍스트 데이터 분석
파이썬 웹크롤링 기초 복습 (2)
못난명서
2023. 1. 12. 23:41
안녕하세요?
오늘은 저번시간에 배웠던 파이썬 웹크롤링으로 네이버 영화 사이트에서 영화 하나를 골라 그 영화의 제목이나 줄거리, 출연진들을 스크래핑해보았습니다.
매우 간단하지만 전체적인 흐름을 한번 더 익히는데 좋을 것 같아 해보았습니다. (오늘은 저번시간의 복습이므로 자세한 설명은 생략하겠습니다. )
(전체코드)
!pip install beautifulsoup4==4.9.3
from bs4 import BeautifulSoup
from urllib.request import urlopen
# 1.불러오려는 url 입력하기 (네이버영화 -> 스파이더맨 노웨이홈)
url = 'https://movie.naver.com/movie/bi/mi/basic.naver?code=208077'
# 2.urlopen 함수를 통해 web 변수를 생성
web = urlopen(url)
# 3.BeautifulSoup으로 web 페이지상의 HTML 구조를 파싱
web_page = BeautifulSoup(web, 'html.parser')
# 소활동 1) 영화제목 및 영화줄거리 스크래핑
# 영화제목 출력해보기 : 영화 제목이 담긴 a 태그를 감싼 h3 태그를 먼저 찾고, 그 안에서 a 태그를 찾는다.
title = web_page.find('h3', {'class' : 'h_movie'}).find('a')
print(f'Movie Title: ', title.get_text())
# 영화 줄거리 출력해보기
summary = web_page.find('p', {'class' : 'con_tx'})
print(f'Movie Summary:', summary.get_text())
# 소활동 2) 출연 배우 이름 스크래핑
url = 'https://movie.naver.com/movie/bi/mi/detail.naver?code=208077' # 영화에 대한 배우/제작진 정보가 담긴 페이지
web = urlopen(url)
web_page = BeautifulSoup(web, 'html.parser')
actor_list = web_page.find('ul', {'class':'lst_people'}) # 배우들의 이름이 담긴 div 태그를 먼저 찾는다.
actor_names = actor_list.find_all('a', {'class':'k_name'}) # 찾아낸 div 태그 안에서 배우 각각의 이름이 담긴 a 태그들을 모두 찾는다.
print('Movie Actor : ', end='')
for actor in actor_names:
print(actor.get_text(), end=', ')
그런데 여러 영화들 스크래핑해보면서 좀 문제? 같은게 막 생기는데
줄거리를 스크래핑하면 줄거리가 한줄 두줄씩만 나오는 영화도 있고 영화 출연진들이 스크래핑 되다가 마는 경우도 아주아주 허다하게 생긴다.
왜그런가 하고 질문을 해보았는데
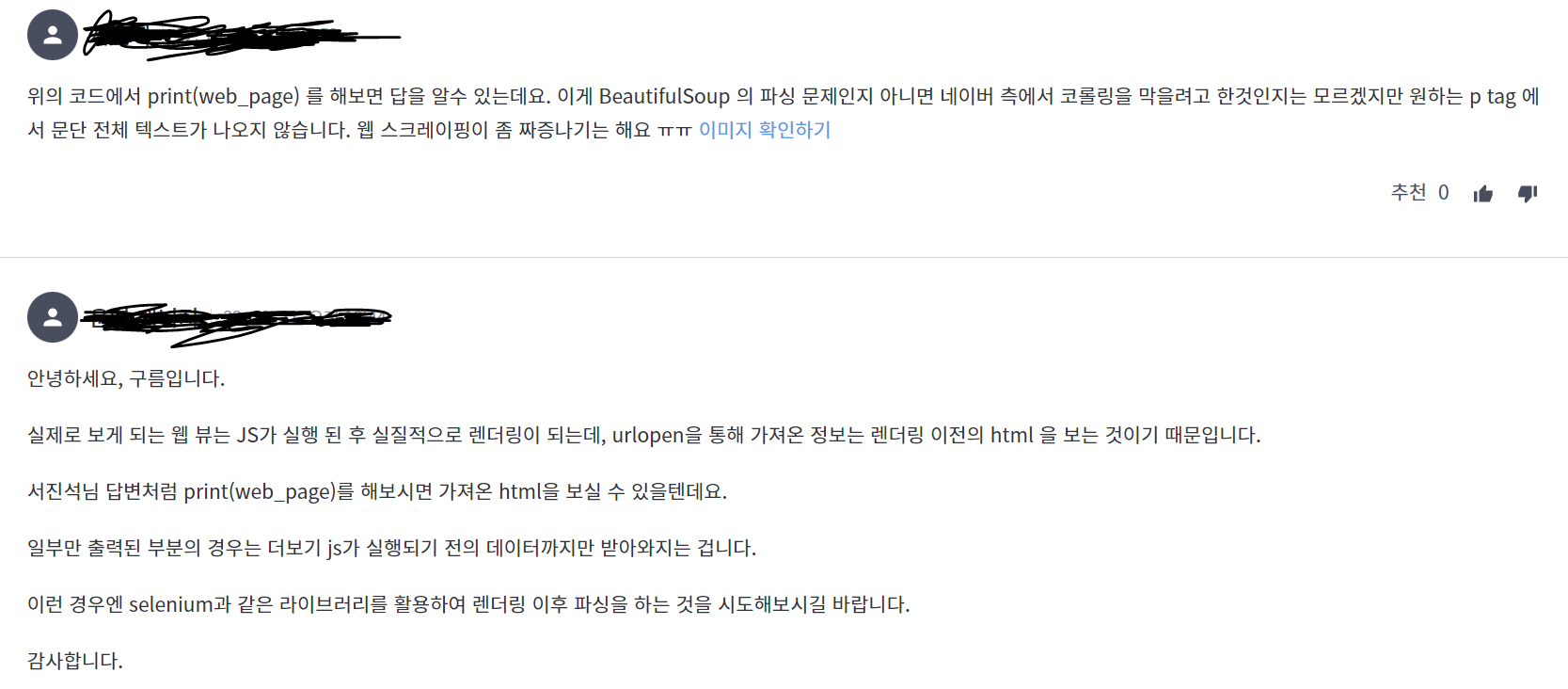
그렇다고 한다 . . . .
얼른 셀레니움 사용법 복습해가지고 가져와야겠다.